
Parametry SMART dysku twardego – odczyt i opis
W dzisiejszym wpisie skupimy się na tym w jaki sposób odczytać parametry S.M.A.R.T dysku przy pomocy jakich programów najlepiej to zrobić, oraz pokrótce opiszemy te najważniejsze.
Co to jest S.M.A.R.T i po co go używać
Na początku odpowiedzmy sobie na pytanie co to jest S.M.A.R.T (ang. Self-Monitoring, Analysis and Reporting Technology) czyli system monitorowania i powiadamiania o błędach działania twardego dysku.
Po raz pierwszy technologia ta została wykorzystana w dyskach ATA-3, oraz późniejszych wersjach. Jej głównym zadaniem jest podnieść bezpieczeństwo przechowywanych danych na naszym dysku twardym. To ona pozwala na ocenę stanu twardego dysku, w momencie gdy awaria jest bardzo prawdopodobna – poinformuje on system oraz użytkownika. System jest skuteczny (potrafi zaalarmować użytkownika o zbliżającej się awarii) w około 30-40 procent przypadków. Dyski twarde bez wyjątku posiadają opcję S.M.A.R.T -zostały one zaimplementowane w celach bezpieczeństwa i wykrywania awarii. Są one włączone automatycznie, gdyby jednak się okazało że nasz dysk nie posiada włączonej opcji S.M.A.R.T powinniśmy ją odszukać i włączyć w ustawieniach BIOSU.
Jak włączyć/wyłączyć opcję S.M.A.R.T w Biosie?
Po wejściu do Biosu odszukujemy w zależności od jego producenta zakładki: Advance Bios Features (lub Boot). Pola podpisane jako HDD S.M.A.R.T. Capability, Hard Disk Smart, SMART for Hard Disk, Smart odpowiadają za włączenie opcji monitorowania dysku, gdyby z jakiegoś powodu były wyłączone.
Programy do odczytu parametru S.M.A.R.T.
Najpopularniejszymi programami, które pomogą w odczytaniu parametrów S.M.A.R.T. są:
Everest
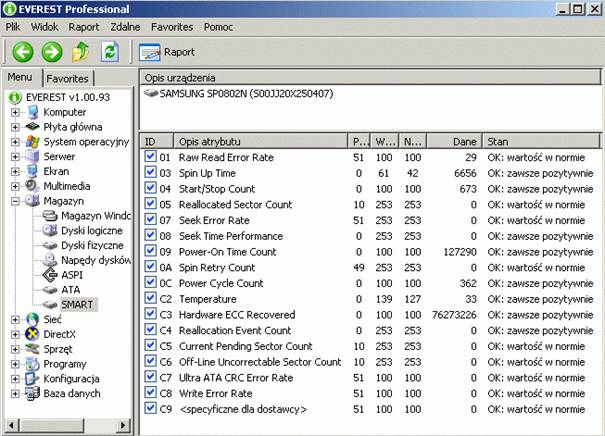
HD Tune
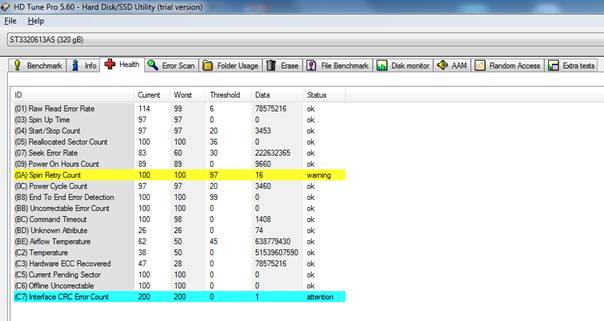
SpeedFan
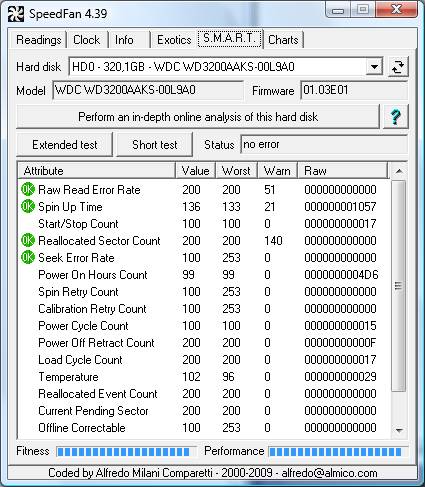
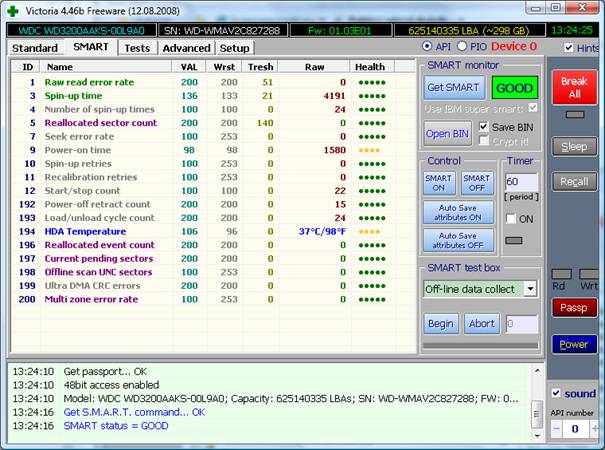
Victoria for Windows
MHDD
Crystal Disk Info
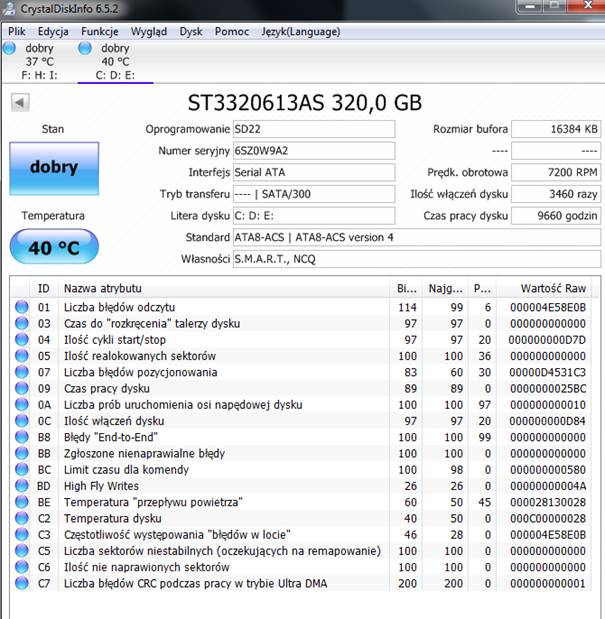
Parametry naszego „Twardziela” jesteśmy w stanie odczytać za pomocą innych programów, których w Internecie można znaleźć całe mnóstwo. Warto jednak pamiętać aby oprogramowanie pobierać ze strony producenta, w celu uniknięcia instalacji niepotrzebnych dodatkowych programów, które jedyne niepotrzebnie zajmują miejsce na naszym dysku twardym, lub co gorsza instalują dodatkowe oprogramowanie w przeglądarkach czy wyszukiwarkach, które w późniejszym czasie utrudniają nam pracę.
Odczyt i opis parametrów SMART dysku
Programem z którym poradzą sobie początkujący na pewno jest Crystal DiskInfo najważniejszą zaletą programu jest opis parametrów jak i całego Menu w języku polskim.
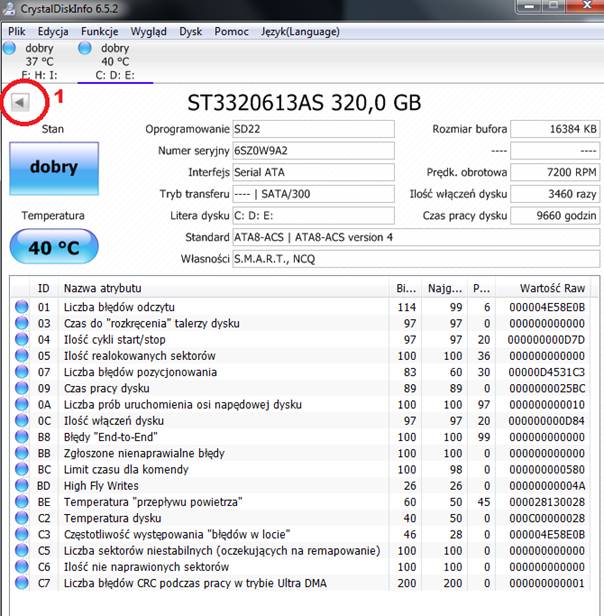
Program w łatwy sposób pozwala się nam przełączać pomiędzy dyskami o ile w sposób fizyczny mamy je zainstalowane. Cyfra numer 1 na poniższym obrazku wskazuje gdzie należy kliknąć aby przedstawić informację dotyczące drugiego dysku.
Dzisiejszy artykuł zawiera informację odnośnie parametrów S.M.A.R.T. dysku twardego dla tego też innymi wartościami nie będziemy sobie zawracali głowy. Na poniższym rysunku numerem 2 oznaczono następujące parametry:
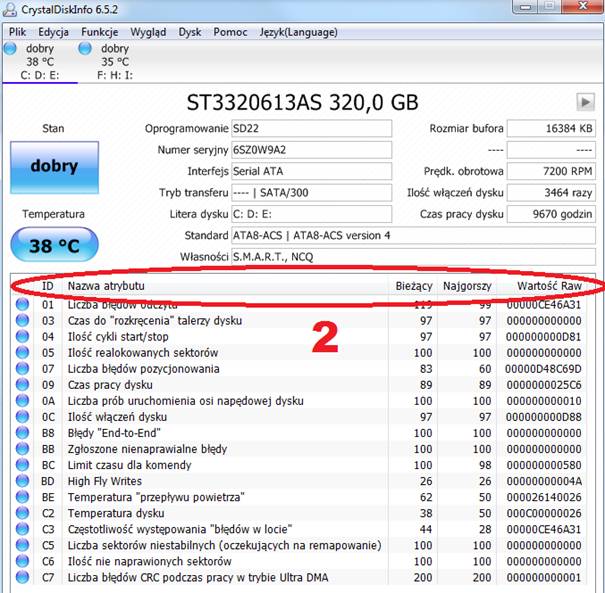
Numer id (ID) – jest to numer w postaci dziesiętnej bądź szesnastkowej, tzw. numer identyfikacyjny
Nazwa atrybutu (Attribute name) – podstawowe atrybuty są wyświetlane przez wszystkie programy, jednak niektóre z nich mogą się różnić w zależności od tego jakiego oprogramowania używamy.
Bieżący (Current) – wartość obecnie odnotowana. Jest to wartość znormalizowana, gdzie znajdują się wyniki kalkulacji danych z postaci Raw przez oprogramowanie dysku twardego. Kiedy wartość Value jest poniżej Treshold świadczy to o awarii dysku, są jednak wyjątki.
Najgorszy (Worst) – jest to najgorsza wartość jaką udało się odnotować elektronice dysku twardego. Najniższa odnotowana wartość Value
Próg (Threshold) – w momencie gdy wartość dziesiątkowa jest mniejsza od tej wartości, jest to informacja że z dyskiem twardym może dziać się coś złego.
Wartość Raw (Raw walue) czyli wartość nieprzetworzona. : surowa (odczytana bezpośrednio) wartość danego atrybutu ukazuje obecny stan dysku. Może zostać zapisana w wartości hexadecymalnej (szesnastkowej) bądź w postaci dziesiętnej, wszystko zależy od tego jakiej wersji programu używamy.
Numer 3 na kolejnym rysunku przedstawia najważniejsze parametry testu S.M.A.R.T:

ID 01 – Liczba błędów odczytu (Read Error Rate) – określa częstotliwość występowania błędów podczas odczytu.
ID 03 – Czas do rozkręcenia talerzy dysku (Spin-Up Time) wartość RAW tego atrybutu oznacza czas w ms (milisekundach) w jakim rozpędzają się talerze dysku (od 0 RPM do pełnej prędkości). Zbyt gwałtowny wzrost tej wartości może oznaczać problemy z dyskiem.
ID 04 – Ilość cykli start/stop – talerzy dysku. Cykl rozpoczyna się przy uruchomieniu dysku, lub przy wyjściu z trybu uśpienia.
ID 05 – Ilość realokowanych sektorów (Reallocated Sectors Count) – Wartość RAW zwraca liczbę remapowanych czyli realokowanych sektorów na dysku twardym. Bad sektory są zamieniane na zdrowe sektory z tzw. puli dodatkowej (rezerwowej), których liczba jest ograniczona.
ID 07 – Liczba błędów pozycjonowania (Seek Error Rate) – kolejnym krytycznym atrybutem jest częstotliwość występowania błędów podczas wyszukiwania przez głowice. Każdy dysk twardy składa się z pozycjonera głowicy, jeżeli system ten jest uszkodzony to liczba błędów bardzo szybko wzrasta.
ID 09 – Czas pracy dysku (Power-On Hours) –Wartość RAW informuje o ilości godzin, które przepracował dysk twardy. W momencie gdy wartość dziesiętna dojdzie do stanu krytycznego, będzie to dla nas informacja, że HDD przekroczył średni czas między awariami MTBF – co nie musi oznaczać od razu problemów z dyskiem twardym.
ID 0A – Liczba prób uruchomienia osi napędowej dysku (Spin Retry Count) – jest to Ilość ponownych prób rozpędzenia talerzy. Wzrost nieprzetworzonej wartości oznacza problemy z mechanicznym podsystemem dysku
ID 0C – Ilość włączeń dysku (Power Cycle Count)
ID B8 – Błędy „End-to-End” (End-to-End error) – mowa tutaj o błędach parzystości, jakie mogą pojawić się podczas przesyłania danych przez cache dysku.
ID BB – Zgłoszone nienaprawialne błędy (Reported Uncorrectable Errors) – błędy, które nie mogły zostać naprawione przez sprzętową korekcję błędów dysku.
ID BC Limit czasu dla komendy (Command Timeout) – Ilość operacji przerwanych z powodu przekroczenia czasu czekania na odpowiedź. Każda inna wartość różna od zera w wartości nieokreślonej RAW informuje nas o problemach z zasilaniem dysku twardego.
ID BD High fly Writes – Głowica zapisująca TF w pewnym momencie może zmienić swoją ustaloną wysokość – mechanizmy wykrywające te zmiany powodują że zapis informacji zostaje przerwany. Wartość RAW określa liczbę wystąpień tego typu błędów w czasie pracy dysku.
ID BE Temperatura „przepływu powietrza” – temperatura powietrza wewnątrz dysku twardego
ID C2 Temperatura dysku – bieżąca temperatura dysku twardego
ID C3 Częstotliwość występowania „błędów w locie” (Hardware ECC Recovered) – Dyski od kilku lat wyposażone są w funkcję korekcji błędów i naprawianie ich. Wartość RAW zawiera ich liczbę – nie jest to jednak dla nas tak bardzo istotne.
ID C5 Liczba sektorów niestabilnych – oczekujących na re mapowanie (Current Pending Sector Count) W momencie gdy z danego sektora nie jesteśmy w stanie odczytać informacji uznajemy go za niestabilny. W momencie gdy próba zapisu informacji w tym sektorze nie powiedzie się, to zostaje on realokowany.
ID C6 Ilość nie naprawionych sektorów (Uncorrectable Sector Count/Offline scan UNC sec tors) – Wartość RAW tego atrybutu informuje nas o łącznej ilość błędów, które miały miejsce podczas odczytu czy też zapisu sektora, a nie mogły zostać naprawione. Zwiększona liczba opisywanego parametru świadczy o problemach z powierzchnią dysku czy też problemach z podsystemem mechanicznym.
ID C7 Liczba błędów CRC podczas pracy w trybie Ultra DMA (UltraDMA CRC Error Count) – Ilość błędów sumy kontrolnej, które zostały wykryte podczas transferu danych przez kabel sygnałowy. W momencie kiedy wartość RAW jest różna od 0 to najczęściej oznacza problemy z kablem sygnałowym.
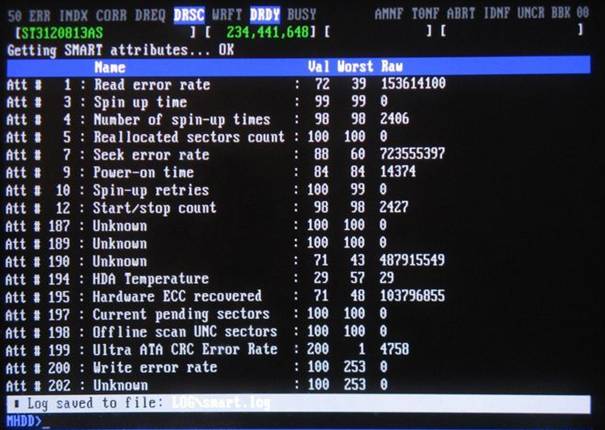
Jak odczytać S.M.A.R.T za pomocą programu MHDD
Opis programu MHDD wraz z instrukcją uruchomienia został już opisany na naszej stronie w artykule MHDD diagnostyka i naprawa dysku twardego. W celu odczytania parametrów S.M.A.R.T musimy wybrać odpowiedni dysk twardy
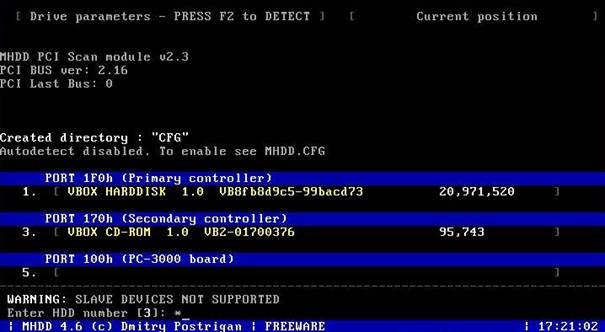
Przy użyciu klawisza F1 wyświetlamy MENU programu MHDD
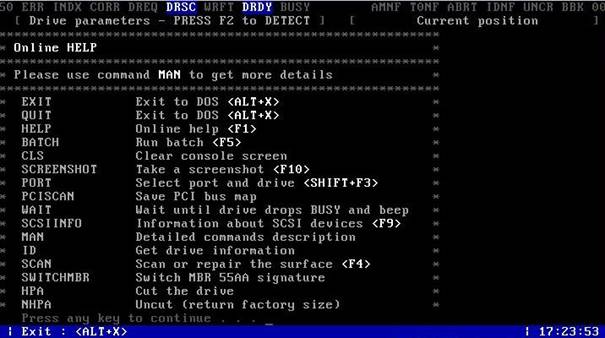
W celu odczytania parametrów S.M.A.R.T wciskamy klawisz F8 lub wprowadzamy komendę SMART
Wyświetli się nam okienko ze smartem dysku twardego.
Podobnie jak w przypadku programu CrystalDiskInfo otrzymujemy następujące informacje:
Numer id (ID) – jest to numer w postaci dziesiętnej tzw. numer identyfikacyjny
Nazwa atrybutu (Name) – podstawowe atrybuty SMART
Bieżący (Value) – wartość obecnie odnotowana. Jest to wartość znormalizowana, gdzie znajdują się wyniki kalkulacji danych z postaci Raw przez oprogramowanie dysku twardego. Kiedy wartość Value jest poniżej Treshold świadczy to o awarii dysku, są jednak wyjątki.
Najgorszy (Worst) – jest to najgorsza wartość jaką udało się odnotować elektronice dysku twardego. Najniższa odnotowana wartość Value
Wartość Raw (Raw ) czyli wartość nieprzetworzona, surowa (odczytana bezpośrednio) wartość danego atrybutu ukazuje obecny stan dysku.Zapisywana w postaci dziesiętnej bądź szesnastkowej.
Za co odpowiadają przedstawione atrybutu już sobie opisaliśmy wcześniej. Pamiętaj aby od czasu do czasu sprawdzić parametry swojego dysku twardego, aby uniknąć przykrych niespodzianek.
Przykład monitorowania SMART dysku twardego pod linuksem oraz jego interpretacja:
W celu sprawdzenia parametrów SMART pod Linuksem służy komenda smartctl
Wpisujemy polecenie: “smartctl -A /dev/nazwa_dysku”, które pokaże nam monitorowane atrybuty (różne w zależności od producenta).
=== START OF READ SMART DATA SECTION === SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 070 066 034 Pre-fail Always - 31424426 3 Spin_Up_Time 0x0003 073 070 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 22 5 Reallocated_Sector_Ct 0x0033 100 100 036 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 085 060 030 Pre-fail Always - 382767487 9 Power_On_Hours 0x0032 086 086 000 Old_age Always - 13080 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 86 194 Temperature_Celsius 0x0022 037 049 000 Old_age Always - 37
Jak to wszystko interpretować? Już na pierwszy rzut oka można zauważyć, że temperatura wynosi 37 stopni Celsiusza (ID 194). W kolumnie “VALUE” znajdują się wyniki kalkulacji danych z postaci “RAW_VALUE” przez oprogramowanie dysku na tak zwane wartości znormalizowane (dla producenta). Jak widać, w tym przypadku żadne przeliczenie nie nastąpiło i obie wartości są takie same. Dane znormalizowane są używane do przewidywania awarii. Jeżeli wartość z pola “VALUE” osiągnie poziom równy lub niższy wartości z pola “TRESH” oznaczać to będzie nieuniknioną awarię dysku (oczywiście pojawi się również odpowiedni komunikat w kolumnie “WHEN_FAILED”). W przypadku temperatury narzucona wartość progowa jest równa zero, co zwykle oznacza brak granicy. Zgodnie z tym co mówi kolumna “TYPE”, temperatura daje nam tylko ogólny pogląd na starzenie się dysku (Old_age). Przykładowo, zużycie mechaniczne ruchomych elementów może zwiększyć tarcie i w konsekwencji wzrost temperatury, tak więc my, mierząc temperaturę, możemy stwierdzić co się dzieje w środku. Kolumna “WORST” pokazuje najgorszą wartość zanotowanego do tej pory parametru. W tym przypadku było to 49 stopni Celsiusza.
Innym, ważnym parametrem jest parametr numer 5. Mówi on o tym ile sektorów zostało automatycznie przeniesione w inne miejsce dysku (przez wewnętrzne oprogramowanie) aby ratować dane. W powyższym przykładzie wartość RAW wynosi 0, więc wszystkie sektory są sprawne. Wartość progowa, która generuje alarm SMART, została określona na 36 (zapewne procent). Jeżeli ilość dostępnego miejsca na przeniesione sektory spadnie do zera wówczas uszkodzone sektory zaczną być widoczne dla systemu operacyjnego (i dane zaczną ginąć bezpowrotnie).
W kolumnie RAW, w pozycjach 1 i 7 widać bardzo duże liczby i wszystkie one dotyczą błędów. Nie należy jednak wpadać w panikę, ponieważ są to wartości “surowe” i tylko producent wie jak je sensownie przeliczyć. Tak więc istotne dla nas tutaj będą wartości znormalizowane. Nawet zanotowane najgorsze przypadki są dwa razy większe od wartości progowej, więc aktualnie nie ma się czego obawiać.
W skrócie, co oznaczają pozostałe atrybuty:
1 Raw_Read_Error_Rate – stopień występowania błędów odczytu nośnika
3 Spin_Up_Time – czas rozkręcania talerzy do obrotów nominalnych
4 Start_Stop_Count – ilość zatrzymań przy przejściu w stan uśpienia
5 Reallocated_Sector_Ct – liczba przeniesionych sektorów
7 Seek_Error_Rate – stopień występowania błędów przy szukaniu ścieżki
9 Power_On_Hours – czas pracy dysku
10 Spin_Retry_Count – ilość nieprawidłowych rozruchów
12 Power_Cycle_Count – ilość włączeń zasilania
Smart dysków SSD
Jeżeli mowa o dyskach SSD znacznie mniejsze jest ryzyko wystąpienia awarii, którą można przewidzieć, gdyż nie mają one części mechanicznych, które z upływem lat ulegają zużyciu. W przypadku takiego rodzaju dysków warto zwrócić uwagę na parametry:
- E7 – SSD Life Remaining – wyznacza ilość pozostałego życia dysku, na początku ma wartość 100 i z czasem spada coraz niżej, a przy wartości 0 może oznaczać bliski koniec przydatności nośnika do użycia.
- F1 – Life Time Writes – określa wartość zapisanych/odczytanych danych wyrażoną w gigabajtach. Dzięki temu możemy dość jasno określić, czy nasz dysk obejmuje gwarancja, gdyż producenci podają przeważnie wartość TBW, czyli liczbę terabajtów danych zapisanych na nośniku, po przekroczeniu której wygasa gwarancja.
Źródła:http://apcoln.linuxpl.org/doku.php?id=smart
Jeśli podobał Ci się artykuł oceń go:
BARDZO FAJNA STRONA MOJE DZIECI uczące się w technikum i gimnazjum, bardzo często korzystają z udostępnionych materiałów. Dziękuję za duży wkład pracy